
One of the most common questions when pulling a model from Hugging Face is : “Will this model fit on my GPU?”
Most people look at the model size on Hugging Face and assume that’s a 14 GB model - “Sure, it’ll fit on my 24 GB RTX 3090. And then CUDA throws an Out Of Memory (OOM) error the moment you increase context length or batch size.
In this post, lets explore hf-mem that automates the memory calculation for LLMs without needing to download the model first.
Automating Memory Calculation #
Calculating GPU memory requirements manually is tedious and error-prone. hf-mem is a CLI tool by Alvaro Bartolome that estimates inference memory usage by inspecting the model’s metadata on Hugging Face—without downloading the weights.
Installation #
The recommended way to install is using uv (for a fast, isolated environment), but pip works too.
# Using uv
uvx hf-mem
# Using pip
pip install hf-mem
Basic Usage #
To check the base memory requirement for a model just run:
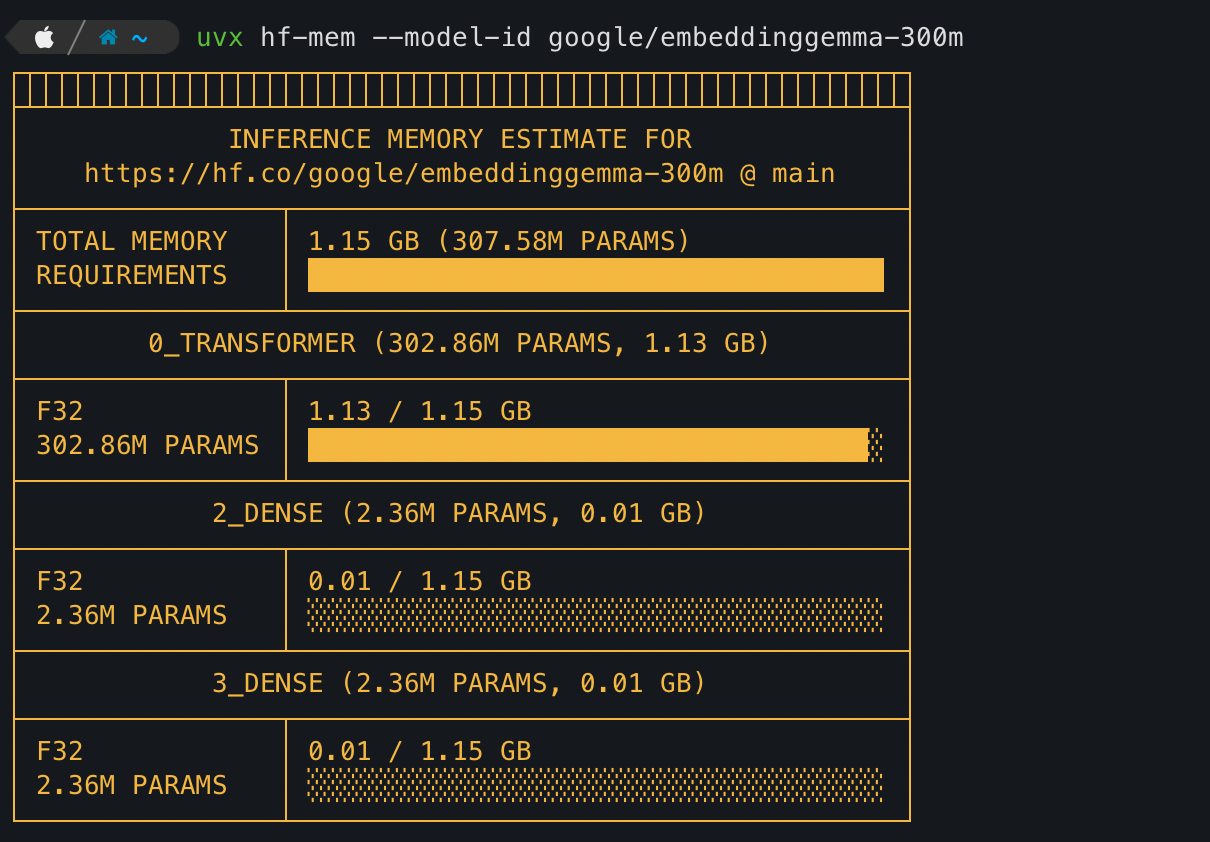
hf-mem --model-id google/embeddinggemma-300m
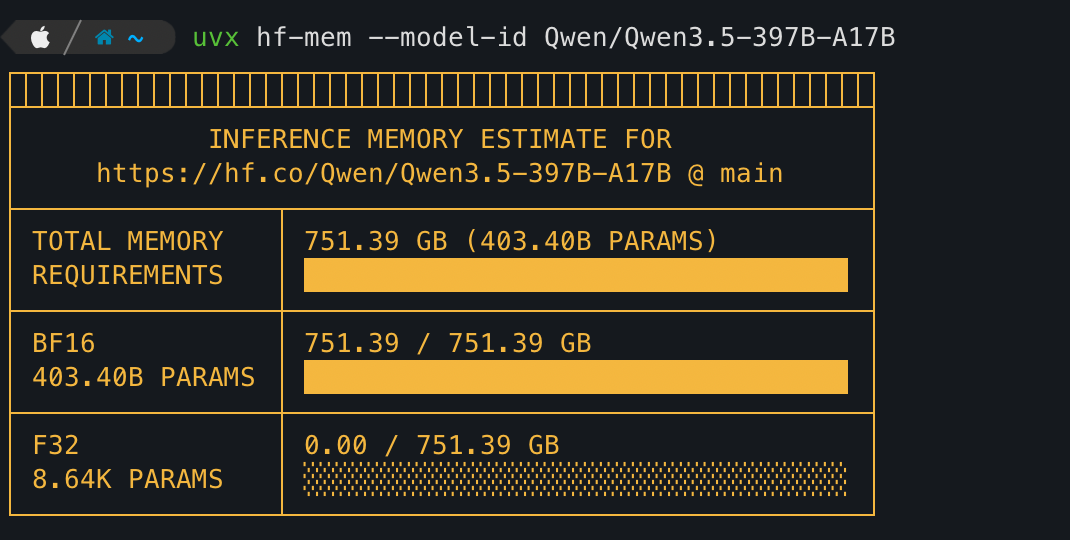
hf-mem --model-id Qwen/Qwen3.5-397B-A17B
Breakdown of output: #
TOTAL MEMORY REQUIREMENTS
1.15 GB (307.58M PARAMS)
The total parameters. is ~307 million and the estimated inference memory - 1.15GB
This is model weight memory, not full runtime memory including KV cache
0_TRANSFORMER (302.86M PARAMS, 1.13 GB)
This means all parameters are in the transformer stack. Doing the math - 302.86M / 307.58M params ≈ 98% of all model parameters live inside the transformer layers
F32 - Float32
This refers to Float32 precision, meaning each parameter in the model is stored as a 32-bit floating-point number. Precision directly determines memory usage.
Doing the math
A single Float32 parameter occupies 4 bytes of memory.
In Transfomer block
302.86M parameters
F32
1.13 GB
which means hf-mem is calculating as - 302.86 million * 4 bytes ≈ 1.13 GB
BF16 (Brain Float16) – 2 bytes per parameter
403.40B PARAMS
BF16
751.39 GB
which means hf-mem is calculating as
403.40 * 2 = 806.8 billion bytes
1 GiB = 1,073,741,824 bytes
806,800,000,000 / 1,073,741,824 ≈ 751.39 GiB